
Yapay zeka alanında yaşanan hızlı ilerlemeye rağmen, en gelişmiş modellerin gerçek dünya koşullarında halen kırılgan olduğu ortaya çıktı. Donanımhaber'in paylaşımına göre Tencent tarafından yayımlanan teknik rapor, yapay zekaların “bağlamdan öğrenme” konusunda ciddi sınırlamalar taşıdığını gösterdi.
Çalışmaya göre, mevcut büyük dil modelleri bağlama dayalı öğrenme yerine büyük ölçüde ön eğitim sırasında parametrelerine gömülen bilgiyi geri çağırmaya dayanıyor. Bu durum, değişken ve karmaşık gerçek dünya senaryolarında tutarlı performans sergilenmesini zorlaştırıyor.
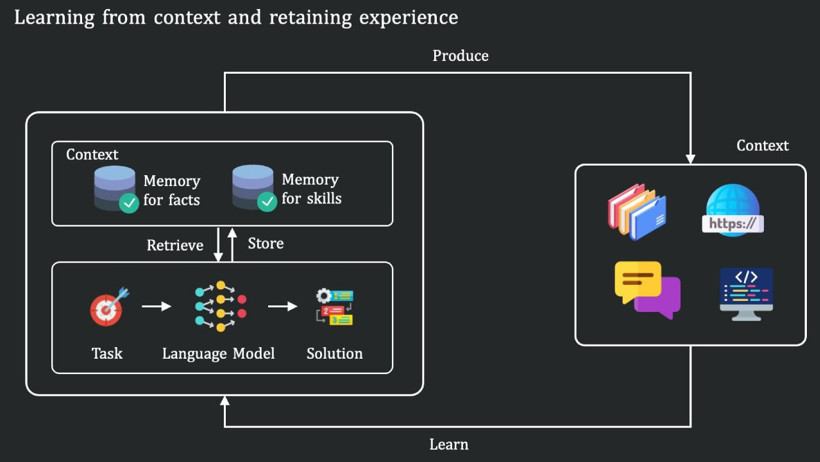
Araştırmacılar, insanlarla yapay zekalar arasındaki temel farkın burada ortaya çıktığını vurguluyor. İnsanlar yeni bir araç ya da problemle karşılaştıklarında mevcut bağlamdan hızla öğrenebilirken, modeller çıkarım aşamasında yeni bilgiyi aktif biçimde kalıcı hale getiremiyor.
Bağlam öğrenmeyi ölçmek için yeni standart
Tencent araştırma ekibi, bu sorunu ölçmek amacıyla CL-bench adlı yeni bir değerlendirme standardı geliştirdi. 19 farklı yapay zeka modeli; 500 karmaşık bağlam, 1.899 görev ve 31 bini aşkın doğrulama kriteri üzerinden test edildi.
CL-bench, klasik bilgi temelli kıyaslamalardan farklı olarak her görevin kendi bağlamını modele sunuyor ve modelin “iş başında öğrenme” kapasitesini ölçmeyi hedefliyor.

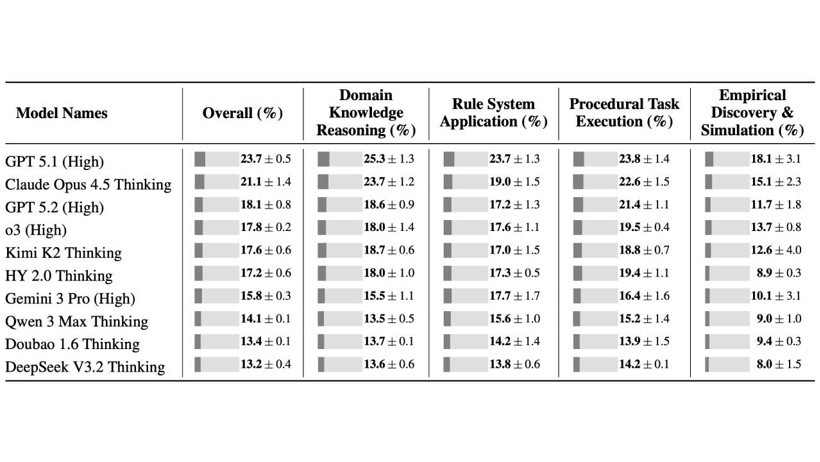
Test sonuçları dikkat çekici oldu. İlk 10 sıradaki modellerin ortalama başarı oranı yüzde 17,2 olarak ölçüldü.
En yüksek performansı yüzde 23,7 ile GPT-5.1 gösterirken, onu yüzde 21,1 ile Claude Opus 4.5 izledi. Çin merkezli modeller arasında Moonshot AI’ın Kimi K2 modeli yüzde 17,6 ile öne çıktı.
Raporda ayrıca bağlam öğrenmenin geçici bir süreç olduğuna dikkat çekildi. Model, bağlam penceresi kapandığında edindiği bilgiyi kalıcı hale getiremiyor.
Kaynak: Diğer / Haber Merkezi


